2025 année charnière de la souveraineté numérique européenne ?
le 15 juin 2026, par - 8 min de lecture
 Lancement du numéro “Un monde sans GAFAM” du magazine “Chut!” à la Gaieté Lyrique
Lancement du numéro “Un monde sans GAFAM” du magazine “Chut!” à la Gaieté Lyrique
Pendant des années quand nous évoquions le logiciel libre, la souveraineté numérique, les réactions étaient polies, intéressées, mais repoussées en pratique : autres priorités, trop risqué, et la sécurité ? En 2025 plusieurs événements ont transformé ce sujet en question opérationnelle concrète : protection des données personnelles, dépendances géopolitiques, modèle économique, sobriété. Alors, comment faire ?
Pourquoi 2025 ?
Le 6 février 2018, la Chambre des Représentants américaine présente à la Maison Blanche un projet de loi intitulé “Cloud Act”. La loi sera adoptée en mars, presque sans bruit en Europe. Et pourtant, elle oblige les entreprises technologiques américaines à fournir aux autorités américaines les données de leurs utilisateurs, quel que soit le lieu où ces données sont stockées dans le monde.
Pour les européens, cela permet aux autorités américaines d’accéder à leurs données sans passer par des procédures juridiques européennes, même si les données sont sur le sol européen dans le cas où elles sont gérées par un service en ligne américain (Google, Meta, Amazon, Apple, Microsoft, etc.).
Et le RGPD ?
Il ne protège pas contre le Cloud Act : dans un avis officiel publié en 2019, le European Data Protection Board (EDPB) et le Contrôleur européen (EDPS) ont conclu que les deux lois créent un conflit irréductible : les entreprises américaines se retrouvent face à un choix impossible — respecter l’injonction américaine et violer le RGPD, ou refuser et risquer des sanctions américaines. Ce dilemme est toujours d’actualité aujourd’hui.
Le 5 novembre 2024, Donald Trump est élu 47e président des États-Unis. 8 ans plus tôt, il avait déjà été élu une première fois et Joe Biden, son successeur, avait fait reprendre un cours “normal” à la géopolitique américaine, ainsi qu’à l’administration fédérale. Beaucoup pensent que ce mandat sera une parenthèse de plus, la dernière puisqu’il ne peut pas se représenter après deux mandats. C’était sans compter le Project 2025 concocté par Kevin Roberts, un fidèle de Trump.
Ce plan a accéléré l’affaiblissement des régulateurs de la vie privée. Il appelle par exemple à restructurer la FTC (l’équivalent de la CNIL) pour la rendre dépendante de l’exécutif, réduisant son indépendance comme régulateur des pratiques des grandes entreprises de la tech. Il est également favorable à un élargissement des capacités de surveillance au nom de la sécurité nationale, avec moins de contrôles judiciaires.
Ces capacités de surveillance étaient déjà énormes suite au Patriot Act (2001), en réaction aux attentats du 11 septembre. Cette loi permet à la NSA et au FBI d’accéder aux données de communication (emails, appels, métadonnées) sans mandat judiciaire, via des ordres secrets, les National Security Letters. Tant et si bien que même des fonctionnaires américains de la NSA s’en étaient émus : c’est ce qui a poussé Edward Snowden à publier des preuves de cette surveillance globale et mondiale.
Le 20 janvier 2025, un ordre exécutif de la Maison Blanche propose, pour les ressortissants étrangers devant demander une autorisation de voyage aux USA (ESTA), qu’ils soient “l’objet d’une vérification et d’un contrôle aussi rigoureux que possible” (“vetted and screened to the maximum degree possible”). Ce qui veut dire par exemple récupérer vos posts sur les réseaux sociaux américains, et vérifier que vous n’avez rien dit ou relayé contre l’Etat américain… ou son président.
Pour résumer :
- Le Patriot Act permet aux autorités américaines de surveiller toute entreprise opérant sur le sol américain (et même européennes), à des fins de sécurité nationale ;
- Le CLOUD act concerne les enquêtes judiciaires ordinaires (criminalité, fraude, etc.) ;
- Le Projet 2025 renforce et étend la concentration du pouvoir exécutif et a été mis en œuvre partiellement par le DOGE, avec à la tête du pays, un président imprévisible et détestant l’Europe ;
- Si l’ordre exécutif du 20 janvier passe et que vous avez dit du mal de Trump sur insta, vos chances d’entrer aux États-Unis seront probablement diminuées.
Ce n’est pas un futur hypothétique. Le procureur général de la Cour Pénale Internationale Karim Khan et le juge Nicolas Guillou se sont vus fermer tous leurs comptes Microsoft suite à la condamnation par la CPI des dirigeants de l’État d’Israël, dont Benyamin Netanyahou. Cela s’est traduit par une grande difficulté à accéder à leurs données et comptes en ligne.
La question n’est donc plus “est-ce que ça pourrait arriver ?” mais “est-ce qu’on est prêts si ça arrive ?”
Ce que ça signifie concrètement pour une PME, une asso, un·e indépendant·e
Vous êtes également concerné. D’autant plus si vous êtes dans des organisations militantes, vous pouvez être ciblé par des mesures de rétorsion de la part de l’État américain. Mais si pour un individu c’est principalement une question de données personnelles, pour une société, c’est également une question de conformité par rapport au secret des affaires, ainsi qu’une question de confiance, d’établissement de partenariats dans la durée.
À cela s’ajoutent des risques plus immédiats :
- Dépendance tarifaire : Microsoft a augmenté ses tarifs de 20 à 25% en 2022, Google a suivi avec une hausse de 20% en 2023 ;
- Discontinuité de service : des outils peuvent être modifiés, dégradés ou supprimés selon des décisions prises dans la Silicon Valley, sans concertation ;
- Entraînement de l’IA : plusieurs services utilisent vos données, pour entraîner leurs modèles d’intelligence artificiell, souvent avec un mécanisme d’opt-out que peu d’utilisateurs connaissent.
Et pourtant des alternatives existent !
La bonne nouvelle, c’est que les alternatives existent et sont de plus en plus matures (et continueront de l’être avec votre aide !).
Vous pouvez consulter une liste d’alternatives chez framasoft, ici ou encore là. Le Collectif d’Hébergeurs Alternatifs, Transparents, Ouverts, Neutres et Solidaires (CHATONS), dont nous faisons partie, est aussi une bonne référence pour des services fiables et respectueux des données.
Par exemple, à la place de Google Drive, vous pouvez utiliser Nextcloud. Pour Office 365, il y a la suite Euro-Office qui sort le 9 juin, pour le mail il y a Iroco bien sûr, mais il en existe aussi d’autres (Tutanota, Posteo, Protonmail). Pour la visio, il y a Jitsi ou BigBlueButton. Pour partager des fichiers lourds, il y a chApril, et ainsi de suite, chaque service en ligne a son alternative.
Nous avons évoqué la protection des données personnelles et l’extra-territorialité du contrôle opéré par les USA. À cela s’ajoutent d’autres aspects positifs :
- Indépendance géopolitique : nous l’avons vu avec le procureur de la CPI, ce sont des “micro-dépendances”, mais que dire des services bancaires qui reposent pour la plupart sur AWS ? Les alternatives opensource permettent de s’affranchir d’une certaine forme de néo-colonialisme numérique ;
- Modèle économique : les startups devenues grandes entreprises du numérique doivent assurer un retour financier à leurs investisseurs, qui attendent plus de résultats financiers, ce qu’Ed Zitron appelle la SaaSflation. Cela pousse les entreprises à aller toujours plus loin dans l’exploitation des données. Les alternatives opensource ne recourent pas à l’extractivisme des données ;
- Sobriété : quels sont les impacts réels de la monétisation des données utilisateurs ? Big data, IA, profilage et ciblage publicitaire : et si nous nous en passions ? Les alternatives opensource sont plus écologiques en étant souvent moins intensives en technologie ;
- Robustesse : le fait d’avoir plusieurs services peut sembler être contre-intuitif : les big techs nous ont vendu des “suites” intégrées qui permettent de conserver les utilisateurs dans leur écosystème. Mais lorsque, pour diverses raisons, cette suite n’est plus disponible, vous perdez votre accès à tous les services. Une série d’outils inter-opérable est une garantie d’amoindrir le blocage des vendeurs et d’avoir une meilleure robustesse de l’infrastructure globale.
Alors, qu’est-ce qui coince ?
La question n’est pas technique. Elle est humaine : quand une personne, une organisation s’est acculturée à un environnement technique, des habitudes de travail, des outils qui fonctionnent (d’autant plus que les meilleurs experts en utilisabilité ont amélioré l’expérience utilisateur de ces suites propriétaires), avec lesquels on a construit une confiance, voire un attachement, comment en changer ?
Comme on dit, on ne reprochera jamais à un DSI de choisir Office 365 ou Google Docs ; en revanche, il se fera virer s’il choisit Euro-Office et qu’il y a des imprévus. Changer, c’est aussi du temps, et prendre ce temps n’est jamais une priorité.
C’est là que se faire accompagner peut permettre de passer à l’action : faire un diagnostic des adhérences techniques, une cartographie des applications, des priorités éthiques et un plan de mise en œuvre.
Par quoi commencer ?
Chaque personne peut essayer des alternatives pour elle-même, si le faire en organisation peut faire peur. Des événements ont lieu très régulièrement pour passer par exemple de Windows à Linux, pour dégoogliser son téléphone android, pour utiliser un autre fournisseur mail que Google, une suite bureautique, etc. Consultez l’agenda du libre et voyez les événements qui ont lieu à proximité de chez vous.
Nous sommes par exemple aux samedis du libre à la Villette à Paris pour discuter et aider à la migration. Nous organisons aussi des événements Tech Care entre midi et deux tous les premiers jeudis du mois.
Et puis, nous pouvons aussi vous faire un diagnostic, sans engagement, pour voir où vous en êtes et ce qui vaut la peine de bouger en premier. N’hésitez pas à venir nous voir ou à nous contacter.
Retour sur la journée d'écoconception numérique 2026
le 17 février 2026, par - 14 min de lecture
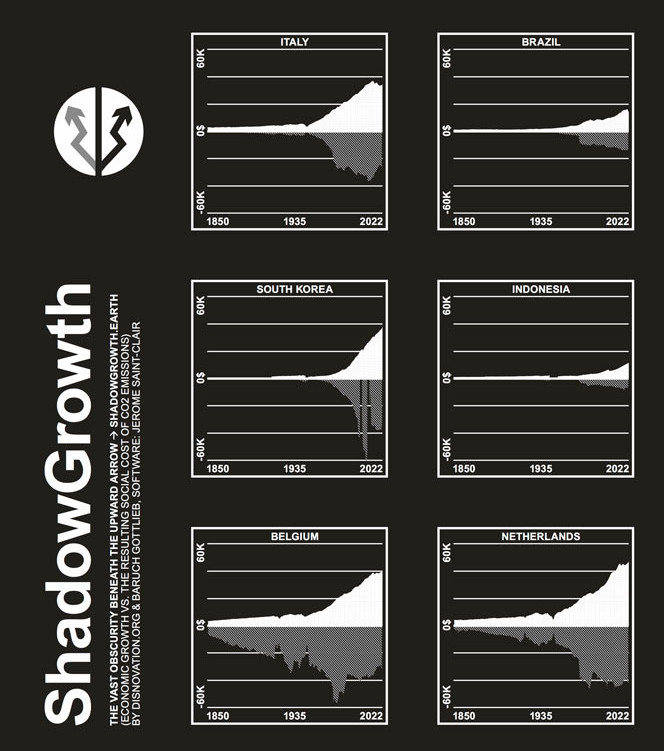
 Shadow Growth de disnovation.org et le jeux Trois Rivières
Shadow Growth de disnovation.org et le jeux Trois Rivières
Les bonnes pratiques de l'IA responsable
le 26 décembre 2025, par - 5 min de lecture
Qu’on parle ou non d’IA, lorsqu’on identifie un besoin dans une organisation, ou dans un contexte personnel, la première question à se poser est souvent la suivante : a-t-on besoin du numérique pour y répondre ? Et si oui, l’IA est-elle réellement nécessaire ? Ou bien une “simple” digitalisation sans IA est-elle suffisante ? Dans ce dernier volet de notre série sur l’IA, nous allons évoquer les bonnes pratiques de l’IA responsable.
Réglementation et souveraineté numérique
le 24 décembre 2025, par - 5 min de lecture
 Photo de Guillaume Périgois sur Unsplash
Photo de Guillaume Périgois sur Unsplash
Les enjeux humains et éthiques de l'IA
le 17 décembre 2025, par - 8 min de lecture
Notre premier épisode résumait le cycle de vie de l’IA et les impacts environnementaux associés. Nous allons voir dans cet article les problèmes liés aux données d’entraînement et aux “travailleurs du clic” qui, tels des turcs mécaniques, rendent l’artificialité des matrices mathématiques intelligentesintelligibles. Nous évoquerons aussi les sujets de transparence et de confiance.